
Website scraping is a complex process. When I started web scraping, I assumed that getting data from a large portion of the internet would be difficult. Once I received a request from a client to scrape Google’s search results, and I assumed that Google would take strong measures to prevent it, given that it was against their terms of service. That kind of severe action, such as completely blocking my IP address, was what I expected.
There are quite a few available tools for assisting with these. However, many of them are subpar at best.
This is where the ScraperAPI comes in super handy. ScraperAPI is an excellent tool that takes care of all the proxies and even CAPTCHAs for you. It is straightforward and easy to use, even if you are relatively new in this field.
As you already know, continuously dealing with IP bans and CAPTCHAs is one of the most annoying aspects of automatic web scraping. With each request, ScraperAPI switches the IP address to counter this.
Submit a URL to their API endpoint or proxy port, and they will handle the remainder for you. This makes it an excellent choice for businesses that wish to harvest Google SERP results for SEO and market research on a budget.

Scraper API Best Values
How Scraper API Works
When scraping the web, you frequently send out thousands, if not millions, of requests. You can get marked before you’ve scratched the surface because a few hundred or even fewer requests are already abnormal.
Most big websites, like Google or Amazon, have their own anti-bot defenses that limit the number of requests you can make from the same IP address in a certain amount of time before you have to fill out a CAPTCHA page.
In situations like these, using a rotating proxy solution is a must because it is impossible to scrape a website at scale without having access to pools of thousands or millions of proxies.
If you rotate proxies, you’ll have the best chance of getting the most complete and precise data collection possible from your web scraping efforts. Every request will be given a different IP, which will help you keep from getting caught. You can obtain this information, especially for any region, when combined with the capability to geo-spread connection threads.
Rotating proxy packages from ScraperAPI automatically provides this feature. They provide you with a proxy port and/or API endpoint to send your requests to in order to integrate, and they take care of everything else.
How to Use ScraperAPI
Using ScraperAPI is pretty straightforward. You must send the URL you want to scrape to the API with your API keys. Afterward, it will return the HTML response to you with your scraped data.
To know more about how ScraperAPI works or how to connect it with your website, please read the official documentation, which explains how to set up different sites in detail. Please click here.
Scraper API Features
ScraperAPI covers almost all the necessary features that you may need for successful web scraping. It is easy to integrate and customize, making the job painless. A few simple tweaks will enable features like JS rendering, IP geolocation, residential proxies, JSON auto-parsing, etc., for you.
The following features are included in all of their plans –
- JS Rendering
- Premium Proxies
- JSON Auto Parsing
- Smart Proxy Rotation
- Custom Header Support
- Unlimited Bandwidth
- Automatic Retries
- Desktop & Mobile User Agents
- 99.9% Uptime Guarantee
- Custom Session Support
- CAPTCHA & Anti-Bot Detection
A bit more detail here.
Captcha: ScraperAPI can easily handle the captcha problem for any site. To test it, you must pick one captcha-enabled website and run the script.
True People Search could be the best place to test the feature, as it shows a pop-up contact form immediately after visiting the site.
Proxy: We’ve tested the proxy feature using different IPs, such as httpbin, and on multiple requests. The IP rotations have worked perfectly. But, it slows down a bit at the time of requests during the IP rotations.
Headless Browser: You can check the differences by running the script on a heavy JavaScript site and checking the differences after removing the render=true.
Speed Test: Hitting a site with ScraperAPI takes fewer attempts than normal ones. See the screenshot below.
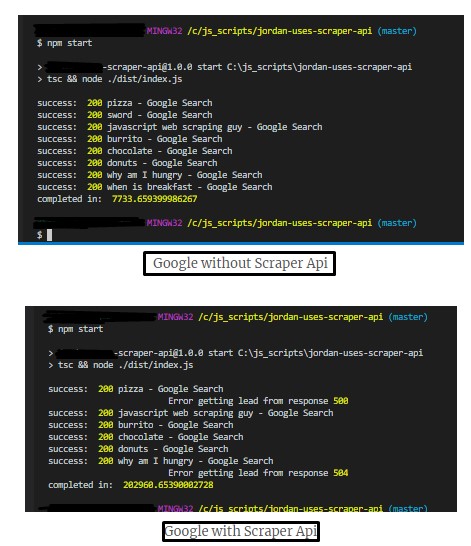
You can see that it took four times longer than usual without ScraperAPI. If ScraperAPI finds an error, it rotates the proxy for 60 seconds and keeps trying until it’s successful. The best part of ScraperAPI is that it doesn’t charge for failed attempts.
ScraperAPI Pricing
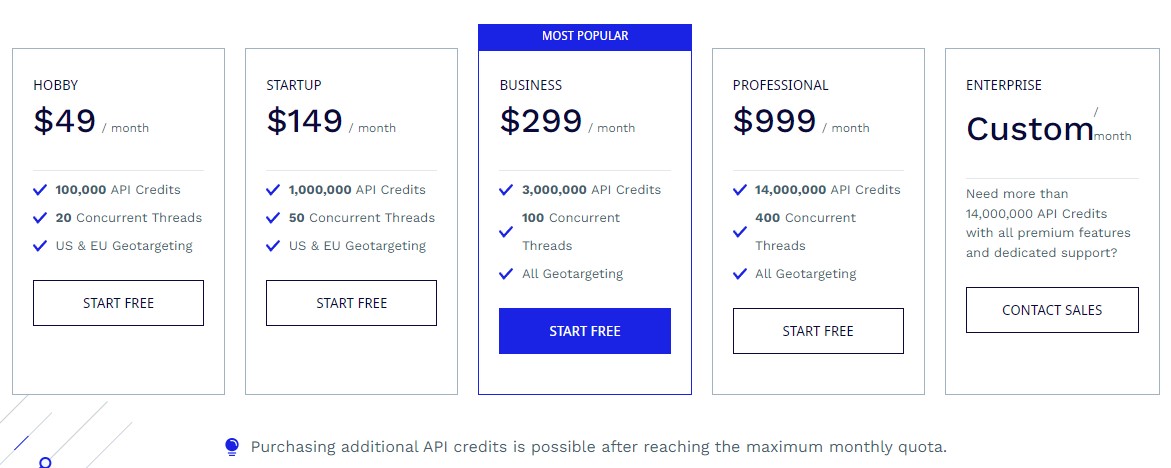
ScraperAPI offers plans for every price range, from $49 for 100,000 Google pages to Enterprise plans for hundreds of millions of Google pages per month.
They also have a free plan if you want to test it out first without committing. You must sign up and receive 1,000 free API credits (with a maximum of 5 concurrent connections).
After setting up an account, you may quickly monitor your API request volume and concurrent request count via the dashboard.
Over to You
ScraperAPI is a robust but easy-to-use web scraping tool. If you want to first test it out before committing, give their free plan a try and then decide for yourself if it is worth your time. It definitely helped in my case.
The Review
Scraper API
With Scraper API, you don't have to deal with the proxies and rotating numerous of IP addresses in order to stay unblocked. Scraper API is smart and does it automatically for you. ScraperAPI handles proxies, browsers, and CAPTCHAs, allowing you to obtain the HTML from any website with a simple API request. With fast support and well-explained documentation, you have certainly the flexibility to scale and use it with confidence.
PROS
- 40M Proxies around the world
- 50+ Geolocations
- 99.9% Guaranteed Uptime
- Unlimited Bandwidth
- Professional Support
- Well Documented
- Affordable Pricing
- Fast & Reliable
- Not tension to Get Blocked
- Scalable Solution
CONS
- Powers Yet Unlocked
- Requires little technical knowhow
Scraper API DEALS
We collect information from many stores for best price available






{kind=link}